How does Search Engine work? Complete Guide to Google Search Engine
The most popular Search Engine: Google Search Algorithms make your websites and web pages available on the Google search engine. But do you know how does this happen? Which process is responsible for making those pages available to Google? How Google ranking system works? This article tells everything about Google and its search algorithms. This will also help you to know how to optimize your websites or webpage.
Pre-requisite Terms
- Crawling
A process in which search engine just like Google or Bing look in or visits a web page. The bots only checks-in for the webpage. Few other names to these bots are Spiders and Crawlers.
- Google Caching
Google takes the snapshots of webpage and websites stored in its servers. The process occurs regularly and helps the web servers to remotely store those web pages and websites. This process is regarded as Google Caching.
- Robots.txt
The crawlers or bots need to visit pages, directories and sub-directories of websites. But how do they choose what should be crawled and what should not? Every website contains sensitive information in various directories like cgi-bin which should not be available to the internet. At a same time, there are few pages that must be available to the internet like Blog pages. Robots.txt file solves this purpose. It basically contains a list of various search engine crawler as well as the list of directories present in the root folder of the websites. These crawlers and directories are defined with permissions to allow or disallow crawling.
Examples are:
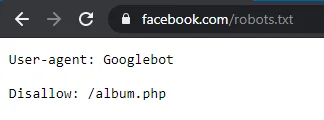
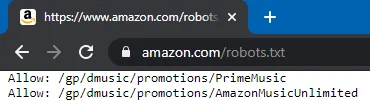
Robots.txt also plays an important role when it comes to Search Engine Optimization.
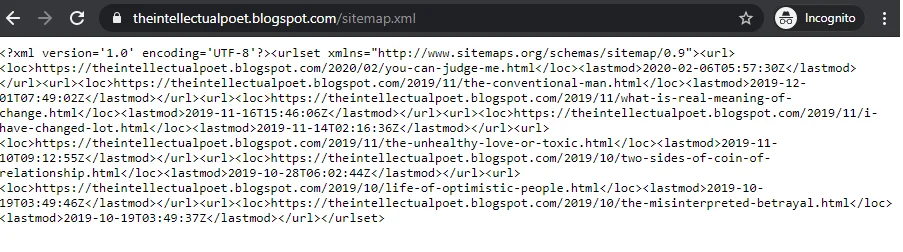
- Sitemaps
Unlike robots.txt, Sitemaps solves the purpose of URL inclusion that helps in smart crawling. Sitemaps includes the URL list along with some information related to each URL like the priority of the page to which URL is pointing. It can also have the date of modification. The main objective of including a sitemap is to link all the pages so that crawler visits all of them.
If anyone manually want to link each and every page, they don’t really need a sitemap, But this scenario don`t look convenient for everyone. Also few search engine auditors like Woorank recommend the use of sitemaps.
- Indexing
When a webpage or website is crawled for the first time and Google cache takes a screenshot and that screenshot is stored in a Google database. Again remember, database only store the screenshots of the page.
- Ranking & Retrieve
The ranking and retrieval process is responsible for showing the most appropriate content. Whenever user types any query, the Google process it in such a way that the pages with most relevant results appear on the first few pages. These results follow various Google search algorithms. Each and every page submitted to Google webmasters get a rank according to which they appear on search engine.
How Google search engine works? Complete process in detail.
- Whenever a person wishes to have a website that appears on Google, the first step involves the designing and development of a website.
- Once the development and designing phase finishes, It is hosted online via shared or dedicated hosting.
- After the second step, the website needs to be submitted to Google Search Console (Google webmasters formerly). This is basically from where website is submitted to Google databases. Google Search Console also helps to check for errors. It monitors and measures the traffic and queries asked by users as well. Crawling means the submission for the first time
- The next step involves the submission of sitemap and robots.txt file to Google search Console. This helps Google page rank algorithms to index all the pages on the website and also disallow the non-permitted directories. Remember these files (sitemap and robots.txt should exist in your website`s file manager as well) Once the crawling completes, the Search Console gives the status about any error. Automatic indexing take place in the absence of errors. The snapshot of websites stored automatically.
- Caching takes place usually after few weeks for a static website or a website in which changes don`t occur regularly. But on a good website like that of a news blog, It takes place daily. You can check the last crawl. Every time after Google caching, the new snapshot replaces the old snapshot indexed.
You can check the last crawl of your website by typing this in navigation bar.
Cache: cache:https://www.yooursite

Now when it comes to retrieval according to a page rank, let us understand some factors that play very crucial role in ranking system of Google.
- Focus Keyword or Phrase: Every page should focus on only one or maximum two keywords.
- Title of the Page: The Focus Keyword should exist in title such that it is the first or second word/phrase of title.
- Meta Description of a Page: Every page on a website should have a meta description which should have that focus keyword in the starting of it. Ideal Meta Description has 152 words and 2 times focus key phrase.
- Number of words on that page: The minimum number of words a particular page should have is 300 excluding the heading, header and footer.
- Number of internal and external links on that page
- The style of writing: Since in Google Caching the snapshot of a page is taken in such a way that all the words like is, am, are, the, will, can be etc. gets excluded from it. Only the main keywords of that page and transition words like also, because exist in that snapshot.

On the basis of the above factors (Google includes many more factors not listed above but for a beginner, taking into consideration the above only can work) In the next Article I will explain all the google Search Algorithms and their working.
Example of an ideal Blog post page given here. Check this out to learn more.
Tutorial to hack a router firmware. Click Here to read
42 thoughts on “How does Search Engine work? Complete Guide to Google Search Engine”
You must be logged in to post a comment.
1starling
1contact
help with coursework https://brainycoursework.com/
degree coursework https://brainycoursework.com/
coursework papers https://courseworkninja.com/
coursework history https://courseworkninja.com/
creative writing english coursework https://writingacoursework.com/
buy coursework https://writingacoursework.com/
coursework writing https://mycourseworkhelp.net/
coursework https://mycourseworkhelp.net/
coursework plagiarism checker https://courseworkdownloads.com/
creative writing coursework ideas https://courseworkdownloads.com/
coursework writers https://courseworkinfotest.com/
coursework website https://courseworkinfotest.com/
design technology coursework https://coursework-expert.com/
coursework writing services https://coursework-expert.com/
coursework marking https://teachingcoursework.com/
coursework writing uk https://teachingcoursework.com/
coursework psychology https://buycoursework.org/
coursework writers https://courseworkdomau.com/
flirt dating site https://freewebdating.net/
free site https://freewebdating.net/
game online woman https://jewish-dating-online.net/
senior bi log in https://jewish-dating-online.net/
adlt dating https://jewish-dating-online.net/
which online dating site is best https://jewish-dating-online.net/
dating service websites https://free-dating-sites-free-personals.com/
free sites https://free-dating-sites-free-personals.com/
singles matching https://sexanddatingonline.com/
italian dating sites https://onlinedatingsurvey.com/
pof dating sites usa https://onlinedatingsurvey.com/
singles chat https://onlinedatingsuccessguide.com/
pof login online https://onlinedatingsuccessguide.com/
dating services online https://onlinedatinghunks.com/
lstill18 single women https://onlinedatinghunks.com/
free local singles https://datingwebsiteshopper.com/
faroedating chat https://datingwebsiteshopper.com/
absolutely free dating sites https://allaboutdatingsites.com/
freedating https://allaboutdatingsites.com/
dating awareness women’s network https://freedatinglive.com/
free local personals https://freewebdating.net/
dating personal ads https://freewebdating.net/